win10下安装splash
安装DOCKER
Docker for windows 仅支持win10专业版,并且电脑需支持虚拟化技术。
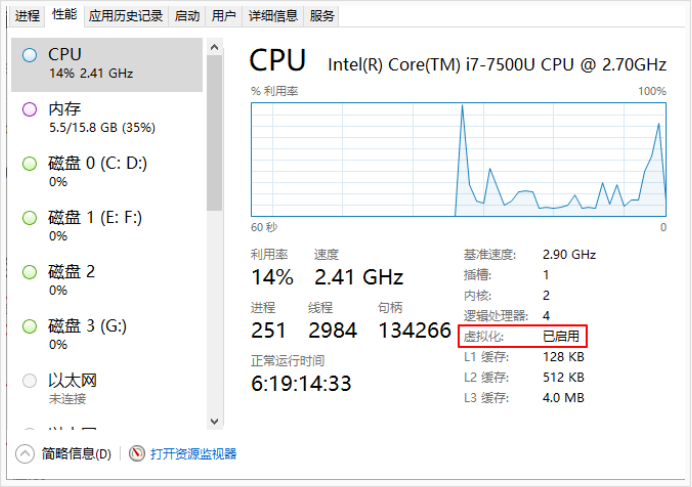
其他版本的需安装Docker Toolbox
国内可以使用阿里云镜像来下载。
下载完成之后直接点击安装。
启动Docker
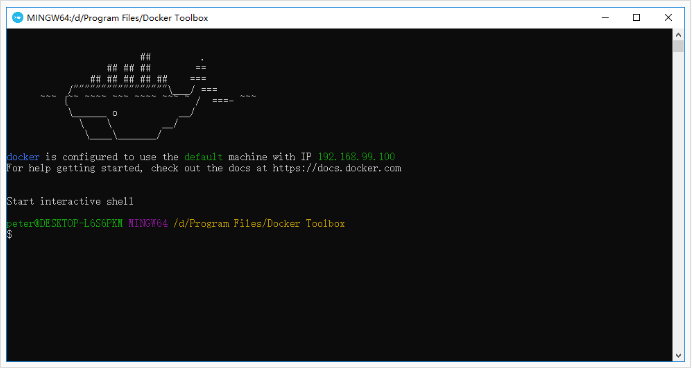
双击Docker QuickStart启动Docker Toolbox终端。
启动后出现错误,卡在了Finalize这一步……
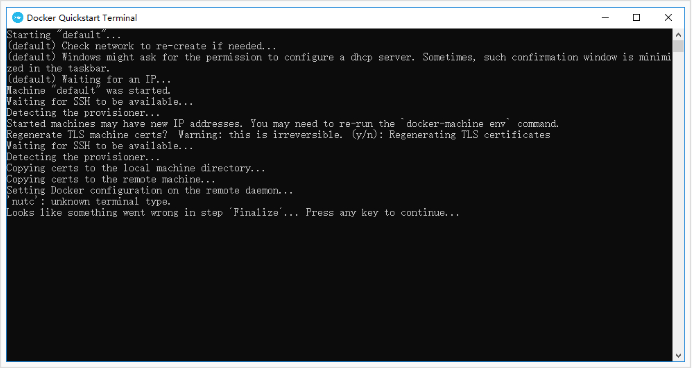
打开安装目录下start.sh文件,将84行的clear注释掉(clear->#clear)。再次启动Docker QuickStart。
安装Splash
执行命令:
$ docker pull scrapinghub/splash
启动Splash
$ sudo docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash
验证
在浏览器输入:192.168.100:8050
显示splash页面